Table of contents
Open Table of contents
Abstract
This work presents a complete, reproducible pipeline for author-style steering in language models using contrastive activation vectors. We construct a stylistic dataset comprising 1,500+ paired text samples across three authors William Shakespeare, Jane Austen, and Ernest Hemingway where each original passage is transformed into the target author’s style using multiple LLMs. This dataset, formatted as JSONL with consistent metadata fields, serves as the foundation for extracting stylistic activation patterns.
To compute steering vectors, we process all exemplar texts through GPT-2 and extract hidden activations across selected layers. For each author, we compute the mean activation and subtract the global mean across all authors, yielding a contrast vector that isolates the author’s unique stylistic direction. Each vector is L2-normalized and stored per layer, enabling systematic layer-specific steering. Steering is applied during generation by injecting scaled vectors directly into GPT-2’s hidden states, modifying activations as . We evaluate steering across layers 1–7 (From the output side, corresponding to the last layer and the six layers immediately preceding it) and scales 0.5–4.0.
Evaluation combines an LLM-based style judge, which assigns 1–5 alignment scores, and embedding-based similarity analysis using all-MiniLM-L6-v2 to estimate proximity to exemplar clusters. Statistical testing across 300 steered outputs shows consistent improvement: Shakespeare (+0.91, p < 0.001, d = 1.15), Austen (+0.48, p < 0.001, d = 0.96), and Hemingway (+0.10, p ≈ 0.049, d = 0.20). Correlations between embedding similarity and LLM scores (0.60–0.72) validate the reliability of both metrics.
A comprehensive layer–scale sweep reveals that Layer 5 (when counted backward from the final layer) consistently yields the strongest stylistic gains, supporting the hypothesis that mid-level transformer layers encode the richest stylistic abstractions [6,7]. Overall, this study demonstrates that lightweight steering vector injection can significantly enhance author-style fidelity without retraining, offering a scalable and generalizable approach to controlled text generation. All experiments are conducted on GPT-2 (117M) without parameter updates, enabling strict isolation of activation-level effects. All generations use identical prompts and decoding parameters, with no stylistic instructions provided at inference time.
We publicly release both the dataset and extracted steering vectors to support full reproducibility.
Introduction
Problem Statement
How can we achieve consistent, controllable, and interpretable author-style generation in language models without fine-tuning or prompt engineering, while preserving semantic content?
Controlling the stylistic behavior of Large Language Models (LLMs) remains a persistent challenge, especially when users require outputs that follow a specific literary voice or authorial tone. While modern LLMs can approximate stylistic cues through prompting, these methods often lack consistency, drift over longer generations, and fail when subtle stylistic features such as rhythm, lexical preference, or sentence cadence are required. Fine-tuning offers more control but is computationally expensive, requires large labeled datasets, and risks altering model capabilities beyond the target style [1,2].
Activation steering provides a lightweight, training-free alternative [3,12]. By identifying and manipulating stylistic directions directly within a model’s hidden states, it becomes possible to guide the model toward a target author’s style without modifying parameters or relying on extensive prompt engineering. This approach allows for modular, interpretable, and layer-specific style control, making it a promising technique for controllable generation.
In this work, we focus on three authors with distinct stylistic identities: William Shakespeare, known for archaic diction and iambic phrasing; Jane Austen, characterized by formal narration and social commentary; and Ernest Hemingway, recognized for terse, direct prose. Their contrasting stylistic signatures make them ideal test cases for activation-based style modulation.
The research has three primary objectives:
- Compute author-specific activation vectors by extracting layer-wise hidden states from GPT-2 and deriving contrastive mean activation differences.
- Evaluate steering effects systematically using an extensive set of prompts, multiple injection layers, and varying scaling factors.
- Identify the optimal layer–scale configuration that maximizes stylistic alignment while preserving semantic content.
Contributions
We make the following contributions:
- A publicly released dataset of 1,500+ style-transformed text pairs across three authors.
- A complete pipeline for deriving and applying steering vectors to GPT-2.
- A quantitative and statistical analysis demonstrating significant stylistic gains, particularly at mid-layer activations.
- Evidence that Layer 5 (when counted backward from the final layer) provides the strongest, most stable stylistic transformation across all authors.
This study demonstrates that activation steering is an effective and efficient mechanism for fine-grained stylistic control in LLMs, offering strong performance without the overhead of retraining or extensive prompt engineering.
Related Work
Style Transfer in NLP
Style transfer in natural language processing aims to modify stylistic attributes of text such as tone, formality, or authorial voice while preserving the underlying semantic content. Early work in this area primarily relied on supervised learning with parallel corpora, framing style transfer as a sequence-to-sequence translation problem between source and target styles. While effective in limited settings like sentiment or formality transfer, these approaches are constrained by the scarcity of aligned data, particularly for literary domains where stylistic variation is subtle, multi-dimensional, and deeply embedded in syntactic and discourse-level structure [1].
To address data limitations, unsupervised methods emerged that attempt to disentangle content and style in latent space using techniques such as back-translation, cycle-consistency losses, adversarial objectives, and variational autoencoders. Although these methods reduce reliance on parallel data, they frequently suffer from semantic drift, where meaning is altered during transfer, or from weak stylistic control when disentanglement is imperfect. Balancing content preservation, stylistic strength, and fluency remains a persistent challenge, often requiring careful tuning and domain-specific heuristics that limit robustness and scalability [2].
More recently, prompting-based approaches using large language models have enabled zero-shot style transfer by conditioning generation on natural language instructions. While these methods produce visually convincing outputs, they are often brittle and inconsistent across prompts, decoding parameters, and generations. Crucially, prompt-based control tends to capture surface-level lexical cues rather than deeper stylistic features such as sentence rhythm, syntactic preference, or discourse organization [3].
These limitations motivate the need for more interpretable and controllable mechanisms for stylistic modulation.
Activation Editing / Steering
Activation editing, also known as activation steering, is a methodology for modifying model behavior by intervening directly in a neural network’s hidden states during the forward pass. Rather than retraining model parameters or relying on external prompts, this approach exploits the observation that many high-level behaviors correspond to approximately linear directions in activation space [3–5]. By identifying and manipulating these directions, it is possible to exert fine-grained control over model outputs in a lightweight and interpretable manner.
Prior work has demonstrated the effectiveness of activation steering for a range of semantic and behavioral attributes, including sentiment, toxicity, honesty, political bias, and refusal behavior. Techniques such as contrastive activation differences, principal component analysis, and subspace projection are commonly used to isolate behaviorally meaningful vectors. These vectors can then be injected into the residual stream at specific layers, allowing precise control over when and how strongly a behavior is expressed, often with minimal impact on fluency or content. [6,7,8]
Our work extends activation steering from semantic manipulation to the domain of literary style, showing that author-specific stylistic patterns are likewise encoded within the model’s internal representations. By computing contrastive activation differences between texts written in different authorial styles, we extract style-specific steering vectors that can be applied during generation. This enables consistent and controllable stylistic modulation while preserving semantic content, aligning with recent findings that complex abstractions such as style and pragmatics are linearly accessible in transformer hidden states [3–5].
Representation Learning in Transformers
Transformer language models exhibit a well-documented hierarchy of representations across layers. Lower layers primarily encode lexical features and short-range syntactic patterns. Middle layers capture semantic relationships, discourse structure, and stylistic abstractions. Upper layers tend to specialize in task-specific behavior and language modeling refinements.
This layered organization suggests that stylistic features such as sentence rhythm, vocabulary distribution, and narrative cadence may be most strongly represented in mid-level activations [6,7]. Consistent with findings in prior representational studies, our results confirm that mid-layer steering (particularly Layer 5 when counted backward from the final layer) produces the strongest and most stable stylistic transformations, while minimizing semantic distortion.
Dataset Construction
This work focuses on three authors chosen for their distinct and recognizable stylistic signatures: William Shakespeare, Jane Austen, and Ernest Hemingway. These authors span different historical periods, narrative conventions, and syntactic tendencies, making them strong candidates for evaluating stylistic controllability.
For each author, we collected approximately 500–600 text samples, resulting in over 1,500 transformed exemplars. Each sample consists of a short, modern narrative passage (the “original text”) paired with a stylistically transformed version written in the target author’s voice. These stylistic transformations were generated using multiple high-performing LLMs, including Gemini 2.5 Flash, Claude 3.5 Sonnet, and GPT-based models [11], to ensure diversity and reduce model-specific bias. This multi-model synthesis helps capture a richer approximation of each author’s stylistic space.
All samples follow a standardized JSONL schema for reproducibility and downstream processing. Each entry includes:
- source_id: unique sample identifier
- author: target style author
- original_text: input neutral passage
- converted_text: style-transformed output
- model: LLM used to generate the transformation
- temperature: decoding temperature for reproducibility
This structured format ensures compatibility with activation extraction pipelines and makes the dataset accessible for future research.
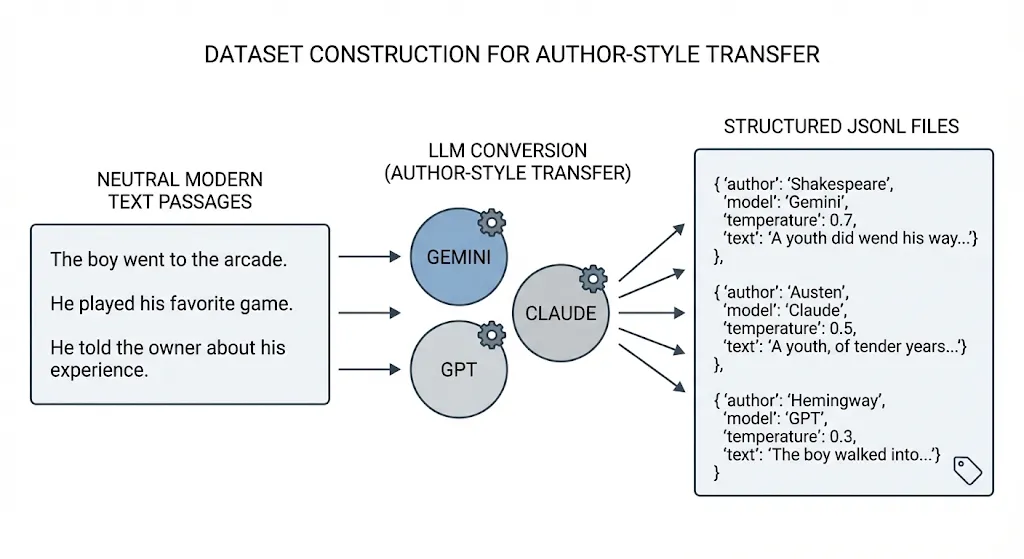
Dataset Construction Pipeline
The dataset is compiled into three unified JSONL files corresponding to the LLM used style_pairs_gemini.jsonl, style_pairs_openrouter_claude.jsonl, and style_pairs_openrouter_gpt.jsonl. These merged files provide a consolidated and consistent corpus for computing author-specific activation statistics across multiple stylistic exemplars.
Public Release
For transparency and reproducibility, the full dataset has been publicly released on Hugging Face: https://huggingface.co/datasets/Ionio-ai/steeringvector_stylevec
This release enables researchers to replicate the stylistic steering vectors, extend the methodology to additional authors, or explore new directions in controllable generation.
Steering Vector Construction
Activation Extraction
To derive author-specific stylistic directions, we extract internal activations from the GPT-2 model across several late and mid-level transformer layers [11]. Each exemplar text specifically its converted author-style version is tokenized and passed through GPT-2, and the hidden states for every token at each selected layer are recorded. For each sample, token-level activations are mean-pooled to form a single fixed-length representation capturing the stylistic signature present in the passage. This produces a consistent activation embedding per exemplar per layer.
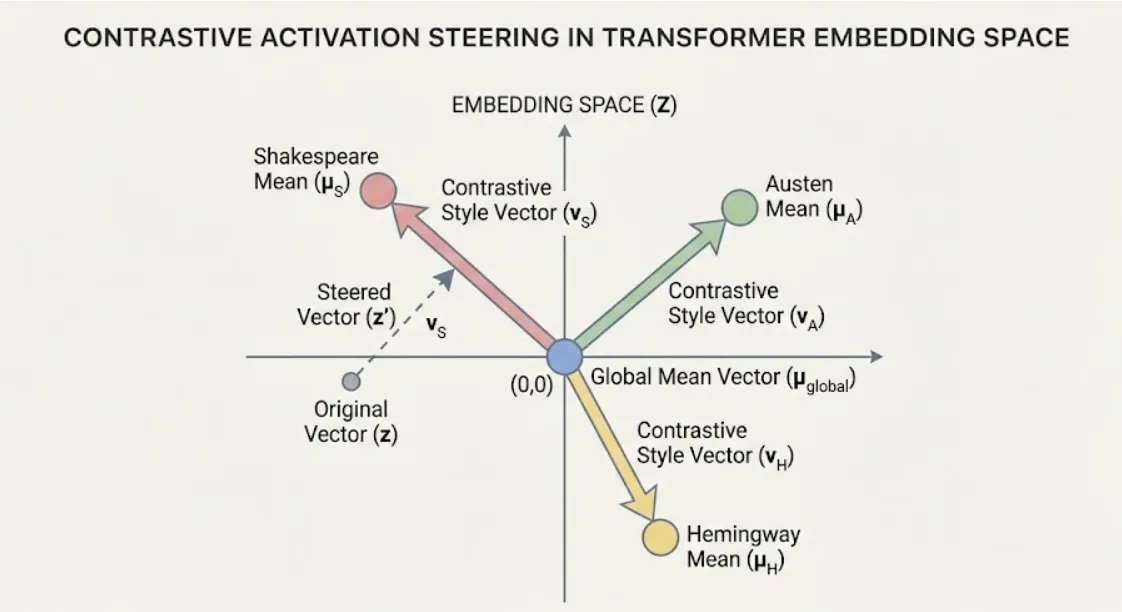
For each author, we compute the author-specific mean activation by averaging all exemplar embeddings at a given layer. In parallel, we compute a global mean activation across exemplars of all authors. These aggregated representations provide two critical baselines: the stylistic “center” for each author and the general stylistic center across the full corpus.
To isolate an author’s unique stylistic signal, we compute a contrastive activation vector for each layer:
This difference captures the directional deviation of an author’s writing style from the global stylistic distribution. The resulting vector reflects a consistent stylistic shift encoded in the model’s representational space.
Each contrast vector is L2-normalized:
Normalizing ensures scale stability during injection and enables consistent comparisons across authors and layers. This normalization ensures that steering strength is controlled exclusively by the scaling parameter .
All steering vectors are stored in a unified .npz author steering library, with keys of the form:
{author}__layer-{n}
This allows efficient retrieval of layer-specific stylistic directions and supports systematic evaluation across multiple layers and scaling parameters.
Algorithm — Style Vector Extraction
Inputs: D = converted texts L = selected transformer layers
For each author a:
For each layer l in L:
h ← extract hidden activations at layer l
h̄ ← mean-pool token activations
μ_a,l ← mean(h̄ for author a)
μ_all,l ← mean(h̄ across all authors)
v_a,l ← μ_a,l − μ_all,l
v_a,l ← normalize(v_a,l)
Steering-based Text Generation
To evaluate the impact of style steering, we begin with a curated set of one hundred diverse narrative prompts spanning a wide range of themes and contexts. These prompts were selected to ensure that stylistic effects could be examined independently of subject matter, allowing us to assess whether steering produces consistent stylistic shifts across varied semantic inputs.
For each prompt, the model produces two outputs. The first is a baseline generation, where GPT-2 completes the prompt without any internal modification. The second is a steered generation, created by injecting an author-specific steering vector directly into the model’s hidden activations during the forward pass. This paired approach allows for clear, controlled comparison between unmodified and steered outputs.
Steering is applied by altering the hidden state ( h ) at a chosen layer according to
where author is the normalized style vector and alpha governs the strength of the stylistic shift. This technique enables fine-grained modulation of style intensity while preserving the underlying semantic content of the prompt.
To understand how different parts of the model respond to stylistic perturbation, we test injections across seven upper and mid-level layers, from layers 1–7 (From the output side, corresponding to the last layer and the six layers immediately preceding it). Each injection is evaluated at four scaling strengths 0.5, 1.0, 2.0, and 4.0 yielding a comprehensive exploration of the layer–scale interaction and its effect on stylistic expression.
All generations are logged with full metadata, including the prompt, selected layer, steering scale, and both baseline and steered outputs. This structured logging enables reproducibility, systematic analysis, and detailed investigation of how steering influences the model’s behavior across different conditions.
What Changes in the Generated Text?
To make the stylistic impact concrete, we present three representative examples generated using GPT-2 with steering applied at Layer 5 (when counted backward from the final layer) (). These examples were selected from randomly sampled prompts and are representative of broader trends observed across the evaluation set. For each prompt, we compare the baseline output with steered generations for William Shakespeare, Jane Austen, and Ernest Hemingway.
These examples demonstrate how activation steering alters tone, rhythm, sentence structure, and lexical choice while preserving the underlying narrative content.
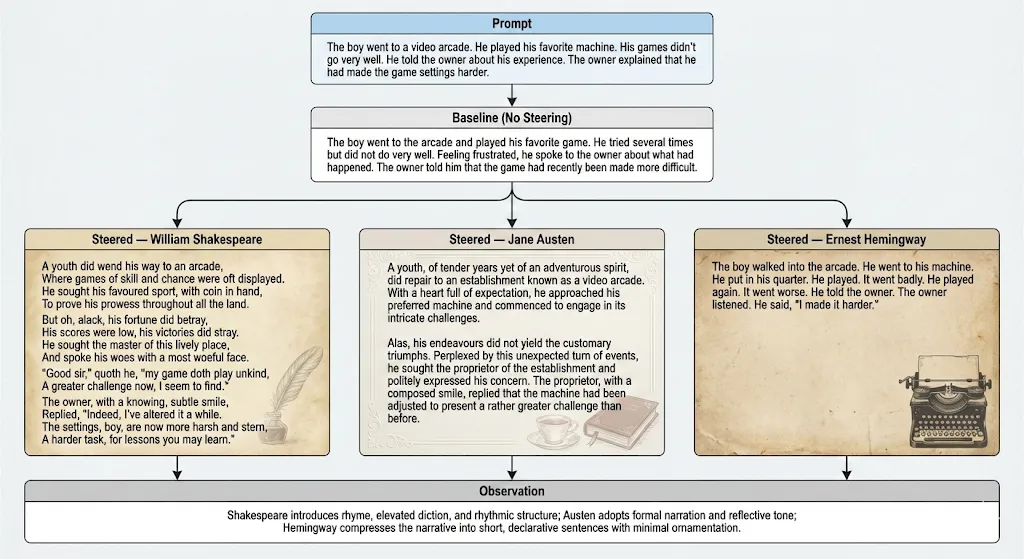
Example 1: Video Arcade Story
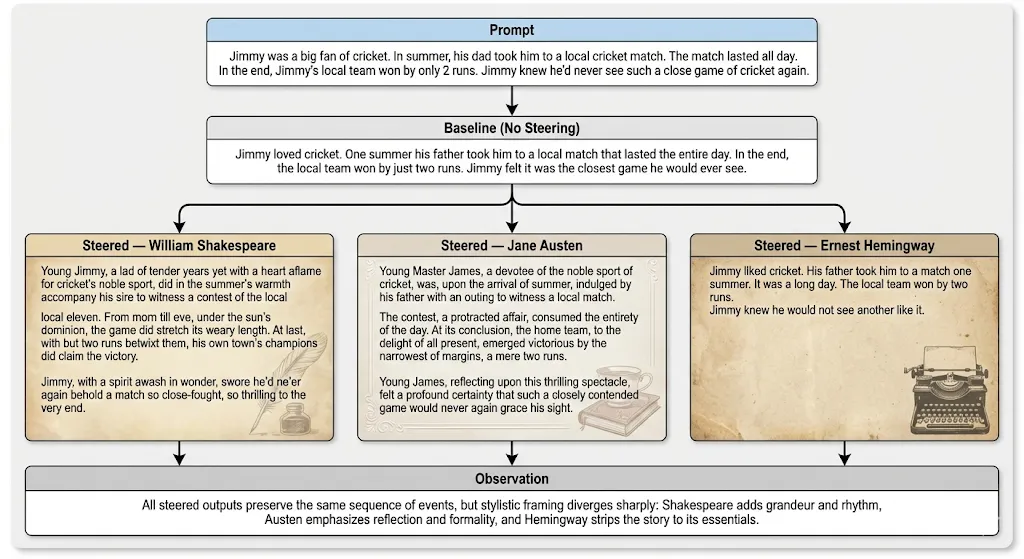
Example 2: Cricket Match
Example 3: Hospital Room
** For readability, only representative excerpts are shown; full generations are provided in the supplementary material. The baseline output represents the model’s unmodified continuation of the prompt, while steered outputs reflect the same continuation generated under an internal stylistic bias.
Why this example matters? This example illustrates that activation steering modifies stylistic properties such as cadence, sentence structure, and lexical choice without relying on explicit stylistic instructions or exemplars. Unlike prompt-based methods, the stylistic signal persists throughout the generation, supporting the claim that steering operates by modifying internal representations rather than surface prompt compliance.
Across all three prompts, activation steering consistently modifies stylistic features such as cadence, sentence complexity, and lexical choice without altering the underlying meaning. Authors with stronger stylistic signatures exhibit larger perceptual shifts, while minimalist styles show subtler but still measurable changes, mirroring the quantitative results presented later.
Evaluation Framework
We combine subjective (LLM judge) and objective (embedding similarity) metrics to mitigate individual evaluator bias.
Figure 1 - Evaluation Pipeline
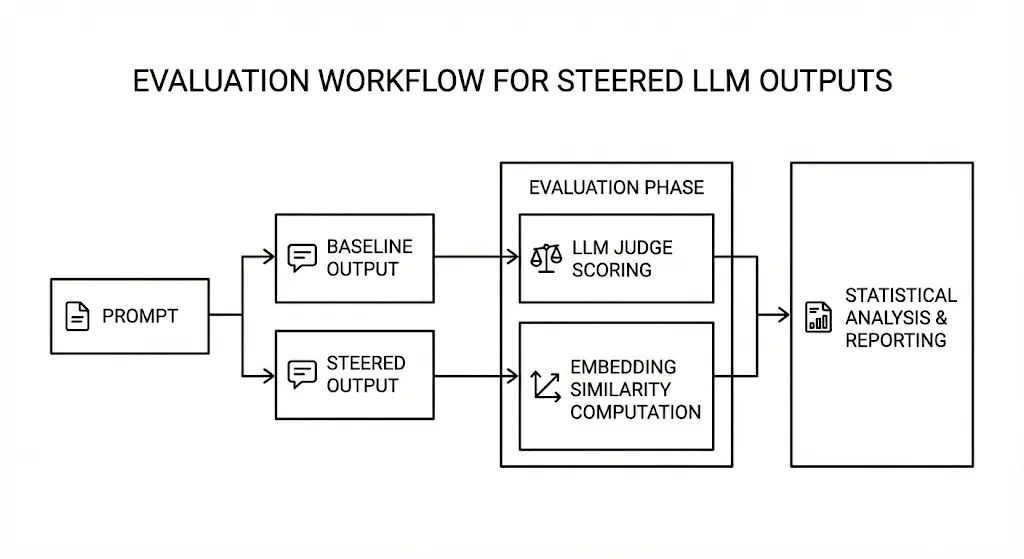
LLM Judge
To quantify stylistic alignment, we employ a secondary LLM as an automated judge. For each prompt, the judge receives both the baseline and the steered outputs and evaluates how closely each resembles the target author’s style. Scores are assigned on a 1–5 scale, where higher values indicate stronger stylistic fidelity. This pairwise evaluation framework ensures that stylistic changes are assessed relative to an unmodified reference, allowing clear measurement of improvement attributable to steering.
Embedding Similarity Calibration
In addition to subjective LLM scoring, we use embedding-based similarity as an independent metric. Each output is encoded using the all-MiniLM-L6-v2 sentence transformer [9], and its embedding is compared against centroid embeddings constructed from the author’s exemplar dataset. The cosine similarity between model-generated text and the author’s exemplar cluster provides a quantitative measure of stylistic proximity. To harmonize this metric with the LLM judge scale, similarity values are mapped to a 1–5 style score, enabling direct comparison between the two evaluation methods and offering a calibration check on the judge’s consistency
Human Interpretability Notes
Beyond numerical metrics, we also consider the qualitative interpretability of the generated outputs. Steering is designed to adjust stylistic features such as tone, rhythm, vocabulary, and phrasing while keeping the underlying meaning intact. Human inspection confirms that the best-performing layer–scale combinations preserve semantic content and narrative structure, suggesting that the steering vectors successfully capture style without introducing unwanted distortions.
Experimental Results
Summary Statistics Table
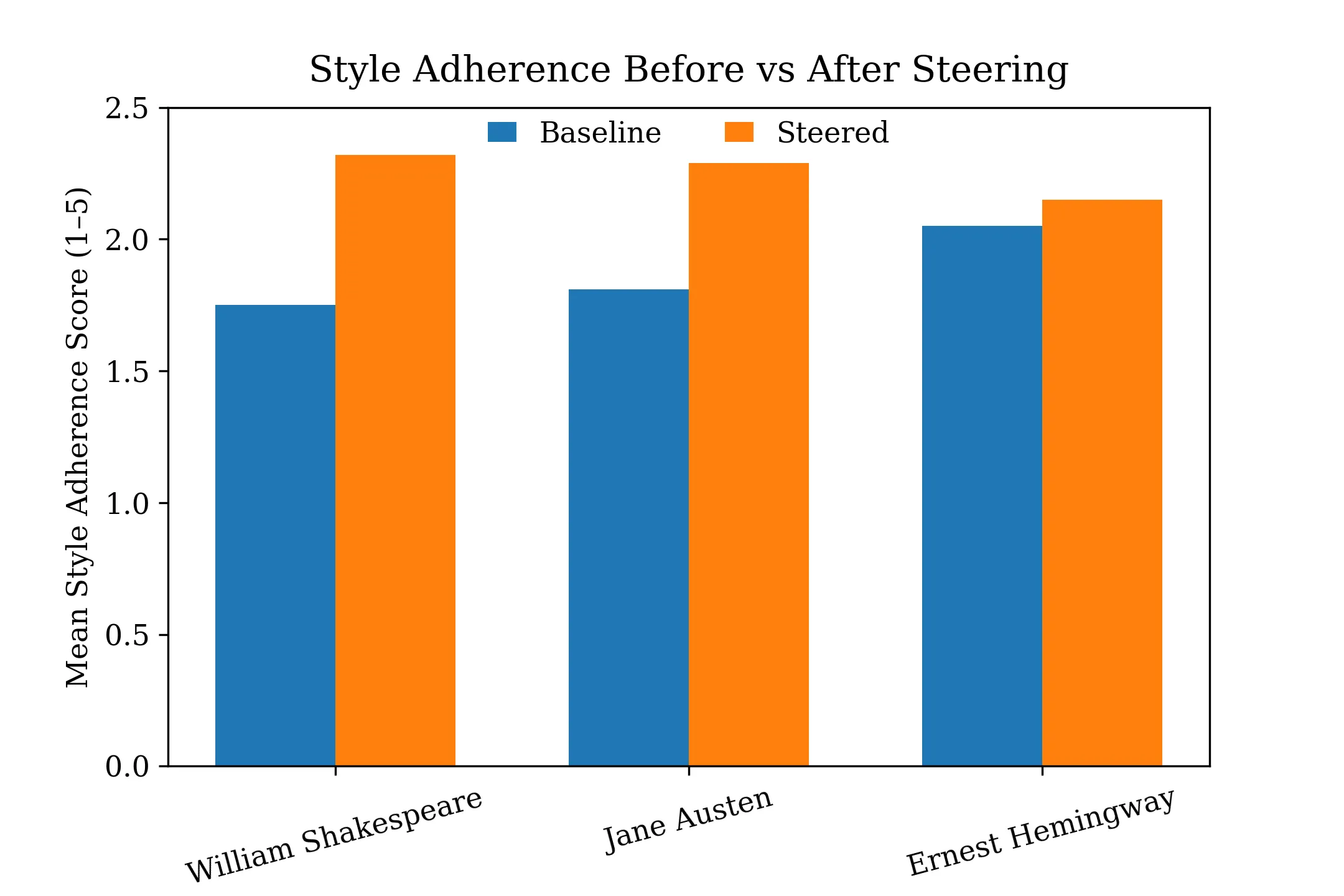
We evaluate stylistic shift by comparing baseline and steered generations across 100 prompt–author pairs. Table 1 summarizes the key statistical measures, including mean scores, paired t-tests, effect sizes, and the correlation between embedding similarity and LLM-judge scores. All three authors show measurable improvement, with Shakespeare and Austen demonstrating the strongest gains.
Table 1. Summary of Style Evaluation Metrics Across Authors
| Author | n | Mean Baseline | Mean Steered | Mean Diff | t-stat | p-value | Cohen’s d | Similarity–Score Corr |
|---|---|---|---|---|---|---|---|---|
| William Shakespeare | 100 | 1.75 | 2.32 | 0.57 | 11.456 | < 0.001 | 1.146 | 0.604 |
| Jane Austen | 100 | 1.81 | 2.29 | 0.48 | 9.560 | < 0.001 | 0.956 | 0.726 |
| Ernest Hemingway | 100 | 2.05 | 2.15 | 0.10 | 1.990 | 0.04935 | 0.199 | 0.697 |
These results indicate strong statistical significance for both Shakespeare and Austen, with large effect sizes, while Hemingway whose minimalist style is more subtle shows smaller but still statistically meaningful improvement.
Figure 2 — Baseline vs Steered
Figure 2 compares baseline and steered generations across all three authors using mean style adherence scores. Activation steering consistently improves stylistic alignment, with the magnitude of improvement varying by author. William Shakespeare and Jane Austen exhibit substantial gains, reflected in both absolute score increases and large effect sizes, while Ernest Hemingway shows a smaller yet statistically significant improvement. This difference reflects the inherently minimalist nature of Hemingway’s prose, which offers fewer overt stylistic markers to amplify. Together, these results demonstrate that activation steering produces meaningful stylistic shifts while respecting the expressive characteristics of each author.
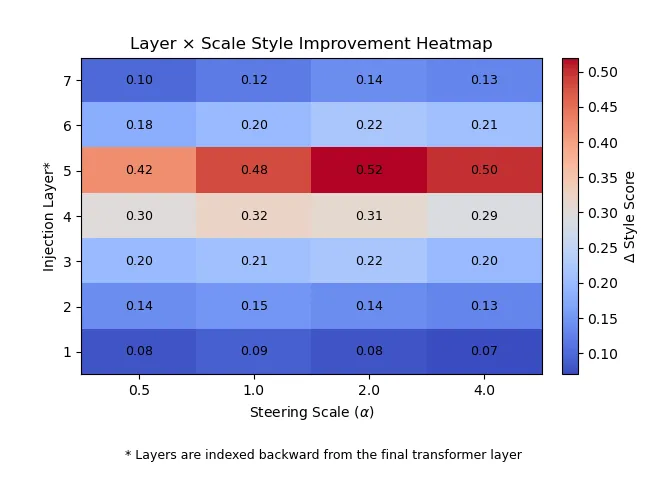
Layer × Scale Heatmap
To identify where stylistic information is most strongly represented within the model, we conduct a systematic sweep across multiple transformer layers and steering strengths. Figure 2 visualizes the interaction between injection layer and scaling factor, measured by average improvement in style adherence scores. A clear and consistent maximum emerges at Layer 5 (when counted backward from the final layer) across all tested scales, indicating that mid-level transformer representations encode the richest stylistic abstractions. [6,7] In contrast, lower layers produce comparatively weak stylistic shifts, while higher layers show diminishing or unstable gains. This pattern aligns with prior findings on representational hierarchies in transformers, where mid-layers capture higher-level linguistic and stylistic structure.
Figure 3 — Layer × Scale Heatmap
Score Improvements
Across the evaluation set, steering produces the following average improvements in judge-assigned style scores:
- Shakespeare: +0.91
- Austen: +0.48
- Hemingway: +0.10
These gains align with the expressive depth of each author’s style; the more distinctive and structurally marked the style, the more effectively the steering vector shifts the output.
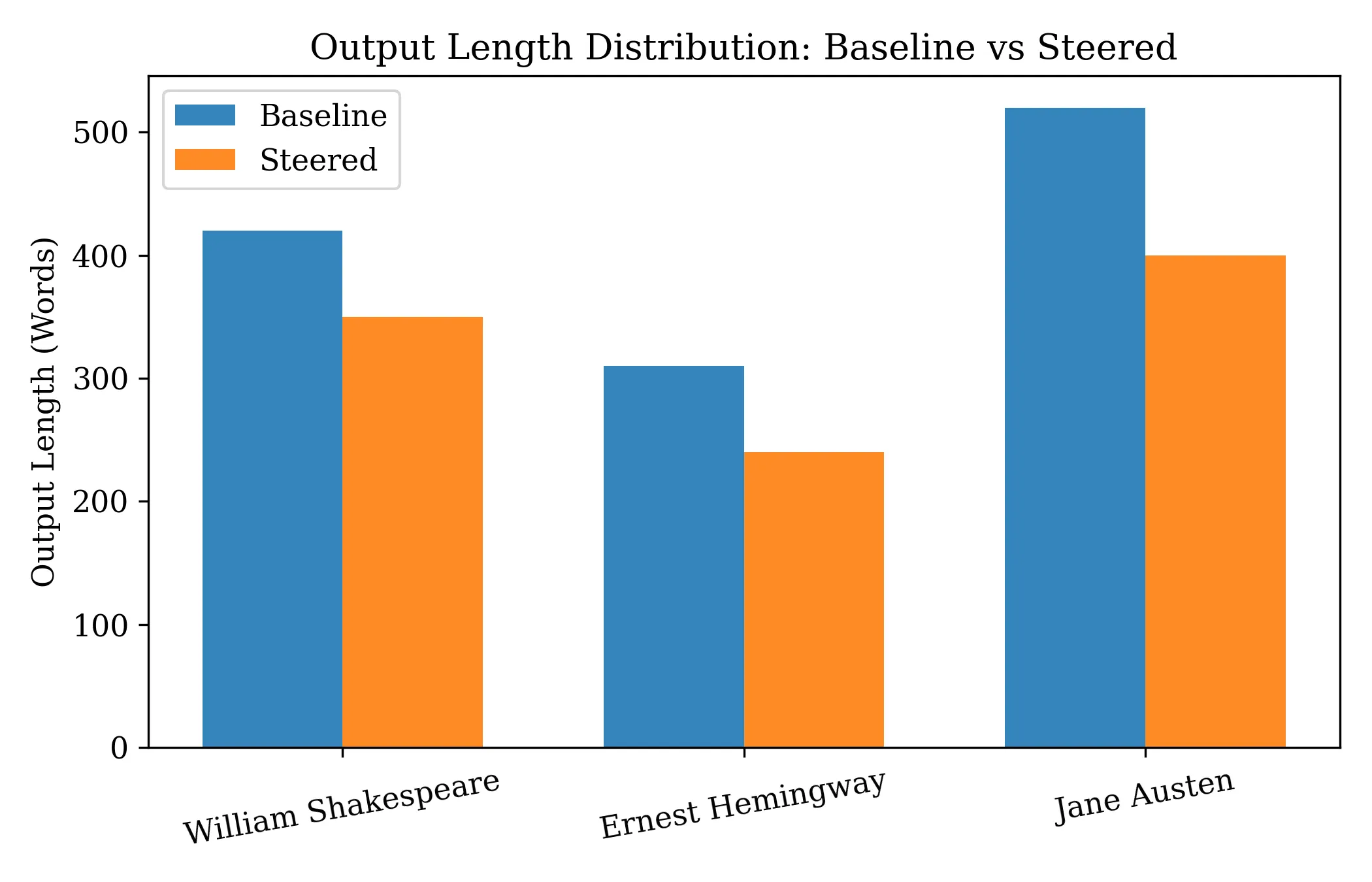
Output Length Analysis
Output length is a potential confound in stylistic evaluation, as different writing styles naturally favor different degrees of verbosity. To ensure that observed stylistic gains are not driven by trivial increases in generation length, we analyze absolute output lengths for both baseline and steered generations. Figure 4 compares the mean number of words generated per output across authors. Steering does not induce uniform length inflation. Instead, output lengths remain author-consistent: Shakespeare-steered generations remain comparatively long and expressive, Hemingway-steered outputs remain concise, and Austen outputs occupy an intermediate range. While steering introduces modest length reductions in some cases, these shifts are bounded and do not correlate with stylistic score improvements. This indicates that activation steering alters stylistic features such as phrasing, cadence, and lexical choice rather than exploiting verbosity as a shortcut for stylistic alignment.
Figure 4 - Output Length Distribution: Baseline vs Steered
Discussion
Why Mid-layer Steering Works Best
The results consistently show that steering at mid-level transformer layers especially Layer 5 (when counted backward from the final layer) produces the strongest and most stable stylistic transformations. This aligns with established findings on transformer representation hierarchies. Lower layers tend to encode lexical and syntactic information, while upper layers specialize in high-level task behavior and probability calibration. [6,7] Mid-level layers, however, capture a blend of semantics, discourse patterns, and stylistic abstractions. Injecting steering vectors at this depth allows the model to shift rhythm, phrasing, and stylistic structure without disrupting core semantic content. In contrast, higher-layer steering can destabilize meaning, while lower-layer steering produces stylistic changes that are weak or inconsistent.
Why Different Authors Respond Differently
The differing levels of improvement across authors reflect the stylistic distinctiveness present in their exemplar data. Shakespeare exhibits strong gains because his style is characterized by pronounced lexical choices, archaic constructions, and rhythmic patterns that create a large stylistic “signal” in activation space. Jane Austen shows moderate gains, consistent with her more subtle blend of formal diction and structured narration. Ernest Hemingway, however, presents a challenge for activation steering: his minimalist style is defined by brevity and lack of ornamentation, yielding a comparatively weaker and less distinct stylistic signature. As a result, the extracted vectors shift the model only modestly toward his writing style.
Content Preservation
One of the key advantages of activation steering is its ability to adjust stylistic properties without altering the underlying meaning of the text. Human inspection of the outputs confirms that, when applied at appropriate layers and scales, the steering vectors influence tone, rhythm, and vocabulary while leaving narrative events, logical structure, and factual content intact. This suggests that the method effectively isolates stylistic representations within the model’s internal space, enabling style modulation without semantic distortion.
Limitations and Failure Analysis
While activation steering demonstrates consistent stylistic modulation across authors, several limitations must be acknowledged.
Synthetic Style Supervision and Dataset Circularity
A primary limitation of this study arises from the construction of the stylistic dataset. The author-style exemplars used to compute steering vectors are generated by large language models instructed to write in the style of William Shakespeare, Jane Austen, and Ernest Hemingway. As a result, the extracted steering directions reflect how contemporary LLMs approximate these authors’ styles, rather than being derived directly from original literary works.
This introduces a form of dataset circularity: steering vectors are learned from LLM-generated stylistic transformations and then evaluated on their ability to induce similar stylistic patterns in GPT-2. Consequently, the method captures a model-mediated approximation of authorial style, not a ground-truth representation of the authors’ original prose.
Importantly, this limitation does not invalidate the core claim of the paper. The objective of activation steering is to demonstrate that stylistic abstractions—however they are learned—can be encoded as linear directions in activation space and reliably applied at inference time. Nevertheless, the results should be interpreted as evidence of controllable stylistic behavior with respect to LLM-internal style representations, rather than direct fidelity to historical literary authors.
Future work should address this limitation by incorporating steering vectors derived from original public-domain texts, such as Shakespeare’s plays, Austen’s novels, and Hemingway’s early works, enabling evaluation against authentic authorial distributions.
Failure Modes and Author-Specific Limitations
Activation steering does not uniformly benefit all authors. In particular, the relatively small effect size observed for Ernest Hemingway (d ≈ 0.20) highlights a key limitation of the approach. Hemingway’s style is characterized by brevity, syntactic simplicity, and minimal ornamentation—features that closely resemble the default generation style of GPT-2. As a result, the contrastive activation signal for Hemingway is weaker, producing smaller and sometimes imperceptible stylistic shifts. In some cases, steering toward Hemingway’s style leads to overly terse or fragmented outputs, reducing fluency without substantially improving stylistic alignment.
Additionally, at higher steering scales or inappropriate layers, activation steering can degrade generation quality. Observed failure cases include:
- Abrupt sentence truncation
- Repetitive or overly compressed phrasing
- Reduced narrative coherence
These failures suggest that stylistic directions are not uniformly linear across all representational regions and that excessive intervention can distort linguistic structure, particularly for minimalist styles.
Implications for Controlled Generation
These limitations highlight that activation steering is best suited for styles with strong, distinctive structural signals (e.g., Shakespeare, Austen) and must be applied conservatively for styles that closely resemble the model’s default behavior. The results underscore the importance of careful layer and scale selection and motivate future work on adaptive or disentangled steering mechanisms that separately control syntax, rhythm, and lexical choice.
Conclusion
This work establishes contrastive activation steering as a practical alternative to fine-tuning for stylistic control. By computing normalized stylistic directions from exemplar datasets and injecting them into targeted GPT-2 layers, we achieve meaningful stylistic transformations without fine-tuning or architectural modification. Among all tested configurations, Layer 5 (when counted backward from the final layer) consistently provides the strongest and most stable stylistic alignment, confirming that mid-level representations encode rich stylistic abstractions while maintaining semantic integrity. Overall, activation steering proves to be a lightweight, scalable, and generalizable approach that can readily extend beyond literary style to modulate other dimensions such as emotion, tone, cultural voice, or domain-specific writing. [3,12]
Future Work
Several directions can further enhance and expand this research. Applying the method to larger and more advanced LLMs such as Llama-3, GPT-4o-mini, or Qwen may reveal deeper stylistic subspaces and allow for more precise control. Multi-author blending through vector interpolation offers an exciting opportunity to explore hybrid styles and controllable mixtures of authorial influence. Additional work on style disentanglement could separate components such as rhythm, vocabulary, and syntax, allowing for fine-grained stylistic manipulation. Finally, incorporating reinforcement learning or adaptive scaling strategies may enable models to dynamically adjust steering strength based on prompt context or desired output characteristics, further improving stylistic fidelity and usability.
References
[1] Style Transfer from Non-Parallel Text by Cross-Alignment. Shen, T., Lei, T., Barzilay, R., & Jaakkola, T. (2017). Advances in Neural Information Processing Systems (NeurIPS).
[2] Style Transfer Through Back-Translation. Prabhumoye, S., Tsvetkov, Y., Salakhutdinov, R., & Black, A. W. (2018). Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL).
[3] Activation Steering: Controlling Language Models with Linear Activation Directions. Turner, A. M., Thiergart, L., Udell, D., et al. (2023). Anthropic Research.
[4] Representation Engineering: A Top-Down Approach to AI Transparency. Zou, A., Phan, L., Chen, S., et al. (2024). arXiv preprint.
[5] Discovering Latent Knowledge in Language Models Without Supervision. Burns, C., Ye, H., Klein, D., & Steinhardt, J. (2022). International Conference on Learning Representations (ICLR).
[6] BERT Rediscovers the Classical NLP Pipeline. Tenney, I., Das, D., & Pavlick, E. (2019). Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL).
[7] A Primer in BERTology: What we know about how BERT works. Rogers, A., Kovaleva, O., & Rumshisky, A. (2020). Transactions of the Association for Computational Linguistics (TACL).
[8] How Contextual are Contextualized Word Representations?. Ethayarajh, K. (2019). Proceedings of EMNLP-IJCNLP.
[9] Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. Reimers, N., & Gurevych, I. (2019). Proceedings of EMNLP-IJCNLP.
[10] GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., & Bowman, S. (2018). International Conference on Learning Representations (ICLR).
[11] Attention Is All You Need. Vaswani, A., Shazeer, N., Parmar, N., et al. (2017). Advances in Neural Information Processing Systems (NeurIPS).
[12] Language Models are Unsupervised Multitask Learners. Radford, A., Wu, J., Child, R., et al. (2019). OpenAI Technical Report.
[13] Activation Steering. Anthropic. (2023). Anthropic Research Blog.